ECCV 2026
Enlightening Photographic Style Transfer with a Self-Supervised Photographic Embedding

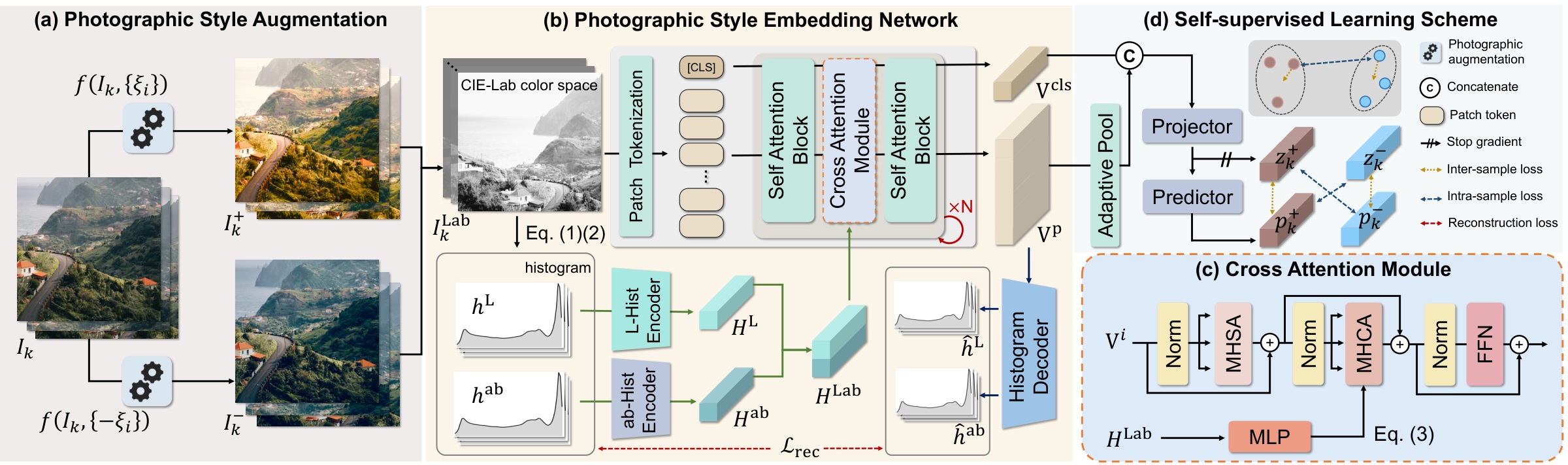
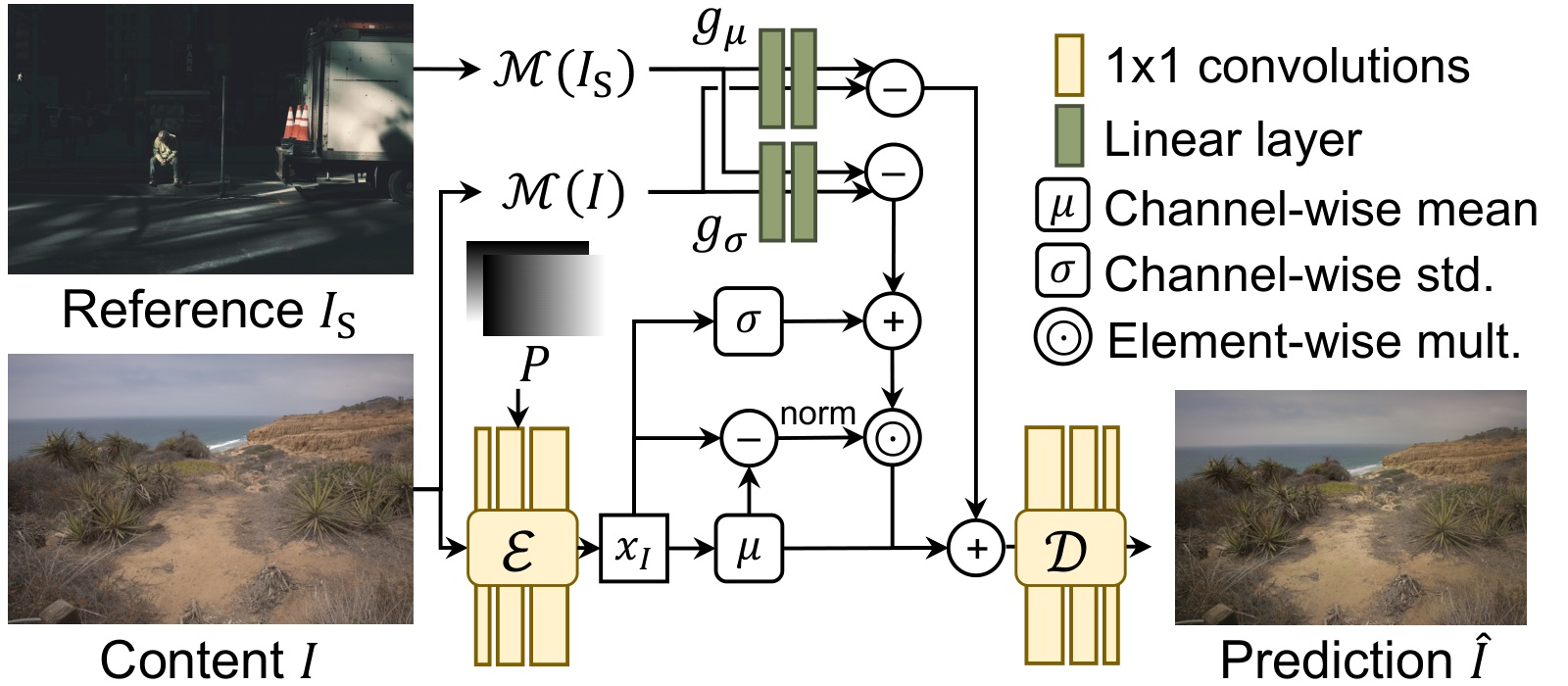
Photographic style — the nuanced play of lightness, color, and tone a photographer crafts — is easy for the eye to read, yet invisible to most image embeddings. We present PETAL (Photographic Embedding for Transfer with an Adaptive LUT): we learn a continuous photographic embedding by self-supervision, and use it to drive a lightweight adaptive neural LUT that transfers style faithfully, with no test-time optimization.